在从零开始手敲次世代游戏引擎(Android特别篇)-1当中我们构建了一个基于docker的Android开发环境,并且实现了我们引擎代码的交叉编译。为了验证我们编译出的程序是否能够在Android设备上正常运行,我们需要构建Android执行环境,并打通编译环境与执行环境,使得我们可以将编译出的程序部署到执行环境当中。
构筑Android的执行环境有两种方式:
-
真机模式: 使用Android物理机(比如手机)运行程序。 好处:真实的性能,真实的环境 坏处:物理机有很多型号,五花八门;收集全需要花很多💰;需要连接物理机,不方便云端调试;需要root手机,不仅麻烦而且会破坏手机的保修,并且给手机带来安全风险(所以最好不要在自己日常用的手机上搞)
-
模拟器模式 使用软件模拟环境运行程序。 好处:方便,省钱,可以远程部署,可以模拟多种型号 坏处:性能与物理机相差甚远,有些基于设备的功能无法测试或者无法完全测试(如GPU,摄像头,附加传感器等)
两种方式各有利弊,实际工作当中的开发往往是两者结合使用。开发前期多使用模拟器模式,后期使用物理机进行最终确认和性能方面的调试优化。
Android的模拟器程序随SDK一起安装,是基于qemu的。qemu是一个开源的虚拟机。因此,在我们前面准备的Docker环境当中,其实已经有了模拟器。不过执行模拟器还需要系统固件,就是我们平常经常说的ROM程序,或者刷机的时候使用的固件包。标准的Android各个版本的固件同样是随SDK提供的,只不过考虑到安装尺寸缺省不会安装,需要通过sdkmanager进行下载安装。
在命令行安装Android系统固件的方法是在安装了Android SDK的环境(如我们的docker环境)当中执行如下命令行:
系统固件有许多版本,可以通过下面的命令行查看所有的选项:
需要注意的就是选用的API版本以及CPU的ABI需要和我们编译代码时的选择相对应。API版本需要不低于我们的选择(我们目前的选择是21,而固件是24,所以没问题),而CPU的ABI必须完全一样。
然后我们需要构建AVD,也就是Android Virtual Device(安卓虚拟设备)。这可以通过下面的命令行实现:
这个命令行的意思就是使用”system-images;android-24;generic;armeabi-v7a”这个固件构建一个名为“test”的虚拟设备。
再接下来我们就可以启动这个虚拟设备了。在Android SDK当中,对于虚拟设备的创建是通过emulator这个程序(其实是qemu的一个wrapper)实现的。通过下面的命令行,可以实现虚拟机的启动:
后面几个选项是关闭音频设备、显示设备、启动动画并开启重力加速度传感器的模拟。这是因为我们是在Docker容器当中启动的模拟器,而Docker容器目前是不支持(如果不做一些很特别的配置)声卡显卡这些设备的。如果我们是直接在电脑上安装的Android SDK,那么其实
就可以了。这种方式能够实际看到模拟器的画面。
好了。现在模拟器已经起来了。如果是本地安装的Android SDK,那么现在应该能看到Android模拟器的画面了。如果是按照本教程使用的docker容器,那么现在看上去什么都没有。为了检查模拟器是否真的启动起来了,我们可以使用adb命令。输入如下命令,就可以看到模拟器的名字:

在模拟器的情况下,名字的后半部分其实就是与模拟器通信的TCP端口号。如果我们启动了多个模拟器,那么这些端口号会按照累增的方式指定。一般第一个是5554。
相对的,如果是使用物理实机,那么首先需要打开开发者选项。在当前主流的Android版本当中,开发者选项缺省是隐藏的。要打开它,首先在物理机上打开“设置 > 关于手机”,然后猛点“版本号”那一行,大约7次之后就会弹出一个对话框,问是否要打开开发者选项,选择“是”。
之后回到设置,就会在列表下方看到多出来一个“开发者选项”。点击进去,首先将第一行“开发者选项”的滑块打开,然后将“USB调试”打开,“监控ADB安装应用”关闭,“仅充电”模式下允许ADB调试打开。设置好了之后,用USB线将设备与电脑连接。如果是Windows电脑的话还需要安装一个手机驱动,如果之前从来没安装过的话(Win10系统的话,一般连接之后Windows会自动提示。老的Windows的话可以通过安装手机自带光盘上的助手程序完成驱动的安装。但是注意助手程序往往会在手机连接的时候抢夺对手机的控制权,所以记得将助手程序关掉)Mac电脑的话,无需任何驱动的安装就可以了。
连接完成之后,执行adb devices命令,就可以看到物理机的名字:

从这里往后的操作无论上虚拟机还是物理机都是一样的。
为了在设备上执行我们编译出的程序,我们首先需要将程序复制到(虚拟/物理)设备上去。这是通过adb push命令来实现的。adb push命令的格式很好理解,基本和cp命令相同,第一个参数是从哪里复制,第二个参数是复制到哪里去。
所以,假定我们编译输出的目录是在build/Test之下,我们要将它们复制到设备的/data/local/tmp目录之下,那么就是这样的命令:
然后,我们可以通过下面的命令进入设备的shell(也就是命令行)
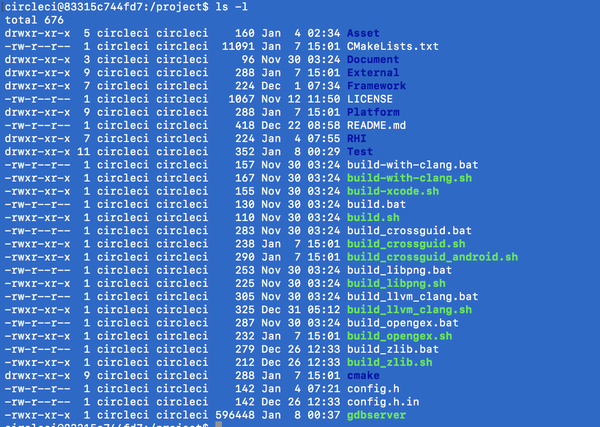
切换到/data/local/tmp目录之下,执行ls -la命令,可以看到程序都已经复制进来了:(截图为写此文的时候的最新版本,包括了一些本篇文章当中尚未介绍的文件,如libMyGameEngine.so。因此如果你的环境里没有这个文件请不要担心)
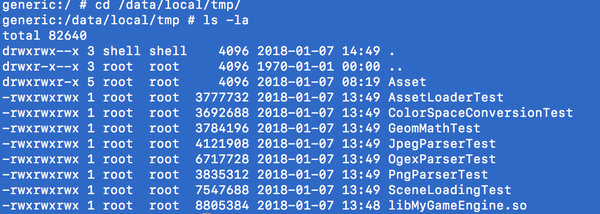
因为有些Test需要加载Asset资源,我们还需要将项目当中的Asset目录复制到设备当中(上图已经是复制好了)。这同样通过adb push命令就可以了。首先输入exit退出设备命令行环境,回到电脑命令行,然后输入:
另外一个需要注意的点是上图当中的程序文件都是带“x”属性的(最左边一列)。这个属性表示可执行。其实在我们运行了adb push之后,这些程序是没有这个属性的。如果我们直接尝试启动它们,系统会报错。因此我们需要执行下面的命令为其添加可执行属性:
(在PC命令行执行的话:)
(OR,通过adb shell进入设备命令行之后执行的话:)
在执行这个命令的时候,如果系统提示权限不够,那么需要先升级到root权限。方法是:
(在PC命令行执行的话:)
(OR,通过adb shell进入设备命令行之后执行的话:)
这里需要特别注意的是,如果是使用的物理机,那么根据你的手机的型号,以及手机是否被root过,上面的命令可能会失败。解决的方法是root你的手机。(如果你不知道root你的手机会带来什么安全风险,请不要进行。最好找一台已经不用的旧手机,重置系统之后进行)
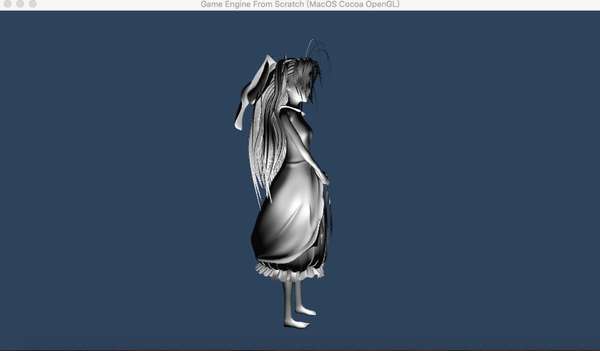
好的。然后再次输入adb shell进入设备环境,切换到/data/local/tmp(因为我们的AssetLoader会在当前目录下查找Asset目录,所以执行之前必须先将当前目录设置为包含Asset目录的目录)并执行这些测试程序。大多数程序应该可以正常执行。
最后,如果想要关闭Android设备模拟器,通过在PC命令行执行下面的命令就可以了:
如果是物理设备,直接拔掉USB线,或者在开发者选项当中关闭USB调试/开发者选项就可以了。
(注意如果是使用的日常使用的手机练习本文,请一定记得在结束的时候关闭开发者选项。否则如果之后使用了社会上一些免费充电设备的话,可能面临数据被盗或者被安装垃圾程序的风险)
(在PS4/PSV的SDK当中,也有类似的命令行程序实现对于SDK相关组件的下载和安装、开发设备的控制。这个过程是非常相似的。只不过PS4/PSV并不支持虚拟机,只有物理机,而这些开发用的物理机是不太容易拿到的。我们可以通过练习Android开发来熟悉嵌入式开发的一般流程)
参考引用